Google 翻譯毫無(wú)疑問(wèn)是目前最好的機(jī)器翻譯工具沒(méi)有之一,如果還有什么能夠超越 Google Translation 那也一定是它自己。
當(dāng)兩天前 Google 推出了全新的整合神經(jīng)網(wǎng)絡(luò)的翻譯工具——GNMT(Google Neural Machine Translation)谷歌神經(jīng)機(jī)器翻譯系統(tǒng),并且這一系統(tǒng)將最先投入到最困難的漢英互譯領(lǐng)域時(shí),科技圈炸了鍋。
在 Google Neural Machine Translation 推出的第二天,「極客公園」受邀來(lái)到 Google 中國(guó)和來(lái)自 Google Brain 團(tuán)隊(duì)的軟件工程師陳智峰聊了聊 GNMT 和機(jī)器翻譯的未來(lái)……
如果機(jī)器翻譯的未來(lái)注定是無(wú)限接近于人,那這個(gè)未來(lái)一定屬于「神經(jīng)網(wǎng)絡(luò)機(jī)器翻譯」。
谷歌神經(jīng)機(jī)器翻譯(GNMT:GoogleNeural Machine Translation)系統(tǒng)實(shí)現(xiàn)了到目前為止機(jī)器翻譯質(zhì)量的最大提升。
相比于谷歌之前基于短語(yǔ)的機(jī)器翻譯(PBMT:Phrase-Based MachineTranslation),GNMT 需要的設(shè)計(jì)工程量更少,同時(shí)翻譯效果更好,講道理的說(shuō) GNMT 的技術(shù)將把機(jī)器翻譯帶到一個(gè)全新的紀(jì)元。
過(guò)去的 PBMT 最讓人頭大的地方在于句子語(yǔ)序,英文到中文的翻譯過(guò)去主要存在的問(wèn)題就是詞序問(wèn)題。之前 PBMT 基于短語(yǔ)的翻譯方式是先把句子分成一個(gè)個(gè)短語(yǔ)和單詞,然后獨(dú)立翻譯,最后對(duì)翻譯出來(lái)的獨(dú)立短語(yǔ)解釋進(jìn)行邏輯整理,變成句子。當(dāng)東亞語(yǔ)言翻譯成歐洲語(yǔ)言時(shí)語(yǔ)序會(huì)有很大變化,單個(gè)翻譯再調(diào)整語(yǔ)序的系統(tǒng)復(fù)雜繁瑣且容易出錯(cuò)。
而 GNMT 則是將整個(gè)句子視作翻譯單元,對(duì)句子中的每一部分進(jìn)行帶有邏輯的關(guān)聯(lián)翻譯,翻譯每一個(gè)字或單詞時(shí)都包含著整句話(huà)的邏輯。
通俗的講,如果將翻譯比作把食物從生變熟,那 PBMT 像把一顆白菜切碎了燒熟再拼湊起來(lái),而 GNMT 則是將整顆白菜放到鍋里煮,變熟后最大程度保持了邏輯原貌。
在使用人類(lèi)對(duì)對(duì)比評(píng)分指標(biāo)時(shí),相較于之前也實(shí)現(xiàn)了極大的提高,在多個(gè)樣本的翻譯中,神經(jīng)翻譯系統(tǒng)將誤差降低了 55%-85%,甚至更高。

在特定的條件下單句的翻譯已經(jīng)接近于人類(lèi),谷歌翻譯團(tuán)隊(duì)會(huì)用一些很特別的句子去測(cè)試GNMT,例如:「小偷偷偷偷東西」,GNMT 對(duì)于這樣類(lèi)似的特殊句子已經(jīng)能夠準(zhǔn)確翻譯。
而 RNN 則是神經(jīng)翻譯系統(tǒng)中最核心的技術(shù),也是讓 GNMT 與眾不同的關(guān)鍵。
RNN(RecurrentNeural Network)被稱(chēng)為循環(huán)神經(jīng)網(wǎng)絡(luò),是機(jī)器深度學(xué)習(xí)的一種人工神經(jīng)網(wǎng)絡(luò),這種網(wǎng)絡(luò)的本質(zhì)特征是在處理單元之間既有內(nèi)部的反饋連接又有前饋連接它是一個(gè)反饋動(dòng)態(tài)系統(tǒng),RNN 一次處理一個(gè)輸入序列元素,同時(shí)維護(hù)網(wǎng)絡(luò)中隱式單元中隱式包含的過(guò)去時(shí)刻序列元素的歷史信息和「狀態(tài)向量」,比前饋神經(jīng)網(wǎng)絡(luò)具有更強(qiáng)的動(dòng)態(tài)行為和計(jì)算能力……
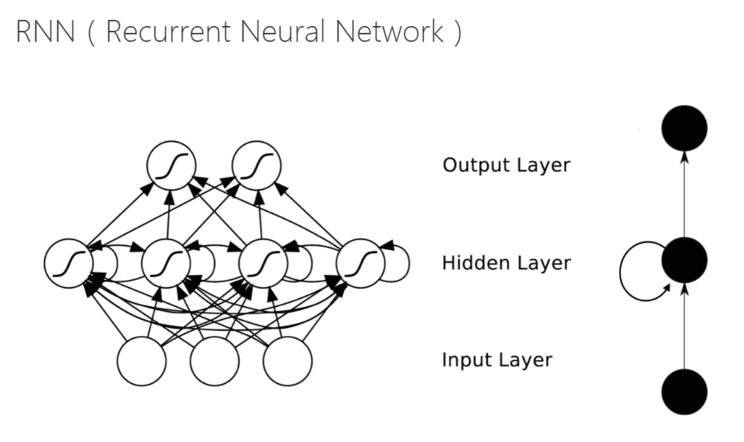
上面這段話(huà)相信很多人都看不懂,所以我們換個(gè)說(shuō)人話(huà)的表達(dá)方式。
傳統(tǒng)多層感知神經(jīng)單元包含了「輸入(Input)」、「處理計(jì)算(Hidden)」和「輸出(Output)」三個(gè)部分,模仿人類(lèi)神經(jīng)原理。
而 RNN 在傳統(tǒng)的多層感知機(jī)基礎(chǔ)上跟時(shí)間沾上邊了,下一時(shí)間點(diǎn)的「處理計(jì)算」會(huì)受上一個(gè)時(shí)間點(diǎn)的影響,會(huì)根據(jù)上一個(gè)輸入輸出的結(jié)果來(lái)調(diào)整當(dāng)前的處理計(jì)算方式,這就讓本來(lái)各自獨(dú)立進(jìn)行計(jì)算的神經(jīng)網(wǎng)絡(luò)有了前后邏輯關(guān)聯(lián)的能力。
直觀(guān)體現(xiàn)就是 GNMT 在 Google 官方的介紹中提到的——Attention 機(jī)制,為了在每一步都生成翻譯正確的詞,翻譯解碼器重點(diǎn)考慮與生成英語(yǔ)詞最相關(guān)的漢語(yǔ)權(quán)重分布(「注意(Attention)」,藍(lán)色鏈接的透明度表示解碼器對(duì)一個(gè)被編碼的詞的關(guān)聯(lián)程度)。
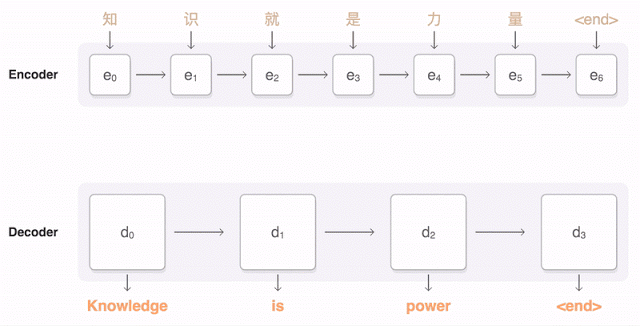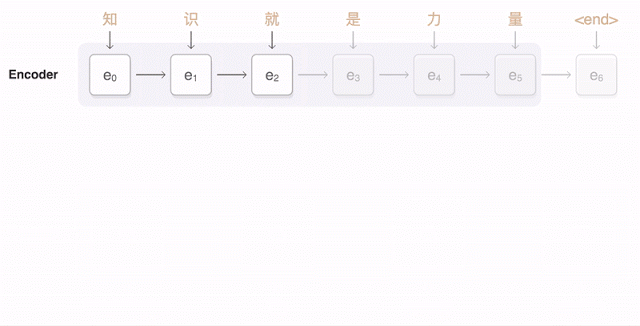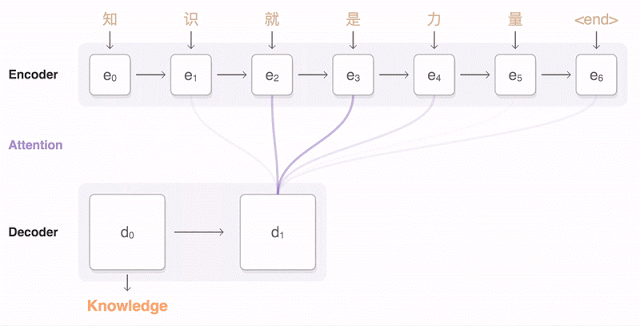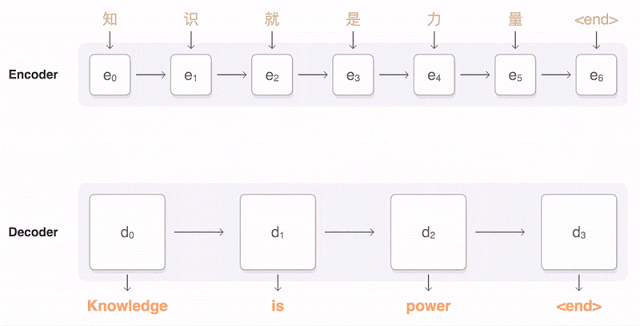
所以谷歌神經(jīng)網(wǎng)絡(luò)翻譯可以把一整句話(huà)作為翻譯單元,翻譯每一個(gè)字詞時(shí)都會(huì)考慮到前面已有的所有字詞含義。翻譯第二個(gè)詞時(shí)考慮第一個(gè)詞的含義,翻譯第三個(gè)詞時(shí)考慮前兩個(gè),第四個(gè)詞考慮前三個(gè)……以此類(lèi)推,于是 GNMT 就實(shí)現(xiàn)了以句子為翻譯單元,翻譯結(jié)果也更加有邏輯性。
RNN 被發(fā)現(xiàn)可以很好的預(yù)測(cè)句子中下一個(gè)字符或下一個(gè)單詞,例如在某時(shí)刻閱讀英語(yǔ)句子中的單詞后,將會(huì)訓(xùn)練一個(gè)英語(yǔ)的「編碼器」網(wǎng)絡(luò),表現(xiàn)為翻譯首單詞的概率分布。如果選擇一個(gè)首單詞作為輸入,將會(huì)輸出翻譯的句子中第二個(gè)單詞的概率分布,并直到停止選擇為止。
不過(guò)原生的 RNN 會(huì)遇到一個(gè)很大的問(wèn)題,叫做 The vanishing gradient problem for RNNs,也就是后面時(shí)間的節(jié)點(diǎn)對(duì)于前面時(shí)間的節(jié)點(diǎn)感知力下降,說(shuō)白了就是健忘,網(wǎng)絡(luò)一深就沒(méi)法訓(xùn)練了,而為了解決這個(gè)問(wèn)題用到的就叫 LSTM,引入了簡(jiǎn)單來(lái)說(shuō)就是你不是健忘嗎?給你拿個(gè)小本子把事記上。
GNMT 的神經(jīng)網(wǎng)絡(luò)就是運(yùn)用了帶有 8個(gè)編碼器和 8 個(gè)解碼器的深度 LSTM 網(wǎng)絡(luò)組成,與其說(shuō) LSTM 是一種特殊 RNN 結(jié)構(gòu),倒不如說(shuō) LSTM 是 RNN 的改良版版,多了記憶單元。?
這是 GNMT 第一次正式上線(xiàn),這也是第一次在傳統(tǒng)的自然語(yǔ)言領(lǐng)域這么大規(guī)模使用新的深度學(xué)習(xí)技術(shù),且這一次最先涉足中英領(lǐng)域。
當(dāng)問(wèn)起為什么選擇最先從中英領(lǐng)域開(kāi)始,Google 的回答主要是兩個(gè)基本考慮:1、中英互譯的需求量很大,且翻譯難度很高,2、整個(gè)項(xiàng)目開(kāi)發(fā)參與者中有很多中國(guó)同事,對(duì)項(xiàng)目開(kāi)發(fā)幫助較大。?
而其實(shí)早在三年前 Google brain 就很想做了這件事了,但當(dāng)時(shí)軟件和硬件都不能夠很好的支持,直到后來(lái)開(kāi)發(fā)出了 Tensorflow 使得訓(xùn)練類(lèi)似的模型可以充分利用分布式計(jì)算,利用很多很多不同的硬件類(lèi)型。另外,一些專(zhuān)門(mén)的硬件加速器也幫助在短時(shí)間內(nèi)完成這個(gè)訓(xùn)練,所以很大一部分原因是因?yàn)檫^(guò)去兩三年 Google 在機(jī)器學(xué)習(xí)、在人工智能方面的巨大投入,使得類(lèi)似的操作才變得可行。
來(lái)自 Google Brain 的軟件工程師陳智峰也表示到目前為止 Google Allo 和 Gmail Inbox 都已經(jīng)開(kāi)始不同程度使用 GNMT,并且 GNMT 的底層技術(shù)模型是可以運(yùn)用到很多領(lǐng)域,很多產(chǎn)品都在這個(gè)基礎(chǔ)模型上都可以做出針對(duì)性?xún)?yōu)化。
雖然已領(lǐng)先時(shí)代,但仍有缺陷
雖然 GNMT 已經(jīng)可以算是領(lǐng)先于整個(gè)時(shí)代,但機(jī)器翻譯的缺陷還遠(yuǎn)未得到完全解決,GNMT 仍然會(huì)做出一些人類(lèi)翻譯者永遠(yuǎn)不出做出的重大錯(cuò)誤,例如漏詞和錯(cuò)誤翻譯專(zhuān)有名詞或罕見(jiàn)術(shù)語(yǔ),這類(lèi)重大錯(cuò)誤往往是因?yàn)橛?xùn)練數(shù)據(jù)里的缺陷,例如「LinkedIn 領(lǐng)英」,如果詞庫(kù)里沒(méi)有 catch up 上這個(gè)特有詞匯,翻譯時(shí)就會(huì)出錯(cuò)。
另外就是雖然現(xiàn)在 GNMT 已經(jīng)可以將句子作為翻譯單元,在翻譯時(shí)考慮整個(gè)句子中每個(gè)字的前后關(guān)聯(lián),但 GNMT 將句子單獨(dú)進(jìn)行翻譯時(shí)還是無(wú)法考慮到其段落或頁(yè)面的上下文的關(guān)系。
機(jī)器翻譯的極限是完全代替人類(lèi)嗎?答案是:并不能全部取代。
要試圖解決這個(gè)問(wèn)題,首先橫在面前的就是深度學(xué)習(xí)基礎(chǔ)算法結(jié)構(gòu)的能力限制,雖然Deeplearning 就是指層數(shù)更多,但這并不意味著更深層、更多的網(wǎng)絡(luò)獲得更好的效果。
雖然按照邏輯應(yīng)該是模型隨著深度的增加會(huì)更強(qiáng)大,但實(shí)際中隨著層數(shù)的增加每次運(yùn)行的計(jì)算量也會(huì)指數(shù)級(jí)增加,當(dāng)超過(guò)一定的量級(jí)反而使得使用反應(yīng)速度下降,所以在目前計(jì)算能力沒(méi)有質(zhì)的突破的情況下,現(xiàn)實(shí)情況下有不同的考慮,并不是越多層越多網(wǎng)絡(luò)就能帶來(lái)越強(qiáng)大的深度學(xué)習(xí)能力。
那這是否意味著目前 GNMT 已經(jīng)到達(dá)了機(jī)器翻譯的極限呢?
陳智峰的回答是:「還沒(méi)有。」
好在現(xiàn)有的深度學(xué)習(xí) RNN 模型還有很多可開(kāi)發(fā)的空間,例如讓模型變得更大或者層數(shù)增加,同時(shí)在該領(lǐng)域每年也都有新的模型出現(xiàn),深度學(xué)習(xí)的模型也會(huì)不斷迭代,所以 GNMT 目前的技術(shù)還遠(yuǎn)未到極限,更加不會(huì)是機(jī)器翻譯的極限。
對(duì)于類(lèi)似面對(duì)更標(biāo)準(zhǔn)化的科技、醫(yī)學(xué)等等固定且有成文規(guī)則的文章機(jī)器可以更快翻譯,準(zhǔn)確率也更高,同時(shí)像是更注重信息類(lèi)的新聞翻譯做的比較好。
完全替換人的翻譯有一定難度,且很有可能是無(wú)法實(shí)現(xiàn)的,因?yàn)楝F(xiàn)有的機(jī)器翻譯都是針對(duì)現(xiàn)在已經(jīng)出現(xiàn)過(guò)的語(yǔ)言現(xiàn)象,但面對(duì)不斷出現(xiàn)不斷發(fā)展的語(yǔ)言來(lái)說(shuō)還是需要人來(lái)不斷創(chuàng)造新詞匯或賦予詞匯新含義。
(編輯:小酷)

掃碼添加客服微信
掃碼關(guān)注公眾號(hào)


酷網(wǎng)(大連)科技有限公司
致力于為客戶(hù)品牌提供完善解決方案
統(tǒng)一服務(wù)電話(huà):0411-62888851
軟件著作權(quán)證:軟著登字第0824158號(hào)
備案號(hào):遼ICP備14000332號(hào)
增值電信業(yè)務(wù)經(jīng)營(yíng)許可證:遼B2-20240418